


Summary
In this low latency world there is a high need of keeping your application as fast as possible. This includes faster computations, faster retrieval of data and hence faster responses.
Now we all have a solution for better and faster computation.. our dear old friend DSA, but what about faster retrieval of data? Our application should not only be highly available but should also respond in milliseconds.
Luckily this is a solved problem by some amazing software architects and the Solution is called Caching
What is Caching?
Caching is storing some temporary data in fast-access hardware memory to enable quicker response for user requests. This way, your code can avoid recalculating results or repeatedly fetching data from the original source, such as a database or another data service.

The benefit of caching is that your turn around time is reduced and your request served immediately. It also improves the system’s overall performance with low latency response by lowering the usage of underlying slow access storage.
Lets move forward with different caching type and strategies and see
- how they can be implemented
- what problems these strategies help solve
| Different Caching types | Some of the most common caching strategies |
|---|---|
| 1. In-memory caching 2. Distributed caching 3. Client-side caching | 1. Cache-Aside 2. Write-Through 3. Write-Behind 4. Read-Through |
Different Caching Types
In-memory caching
In-memory caching is a caching technique where data is stored in a system’s RAM (Random Access Memory) instead of on a disk or in a database. This method is beneficial for applications that need rapid data access, such as web servers and databases. By reducing the number of database queries and disk reads needed to fetch data, in-memory caching can greatly enhance an application’s performance. However, it’s important to remember that in-memory caching is volatile, meaning the data in RAM can be lost if the system is shut down or restarted
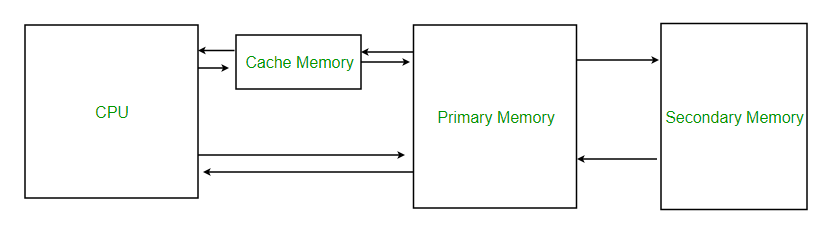
Distributed caching
In Distributed caching type data is stored across multiple servers or nodes within a network. This approach is beneficial for applications that need high availability and scalability. By distributing the workload of storing and retrieving data among multiple servers, distributed caching can enhance the application’s performance and minimize the risk of data loss.
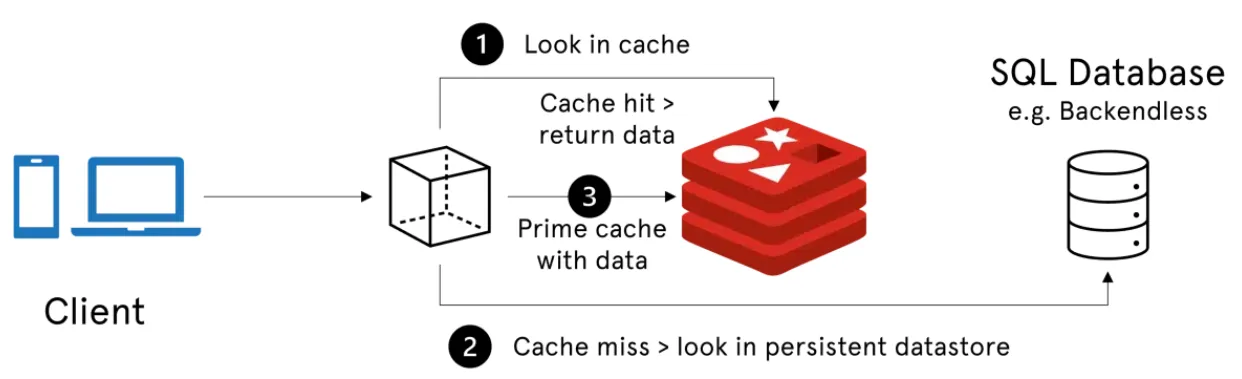
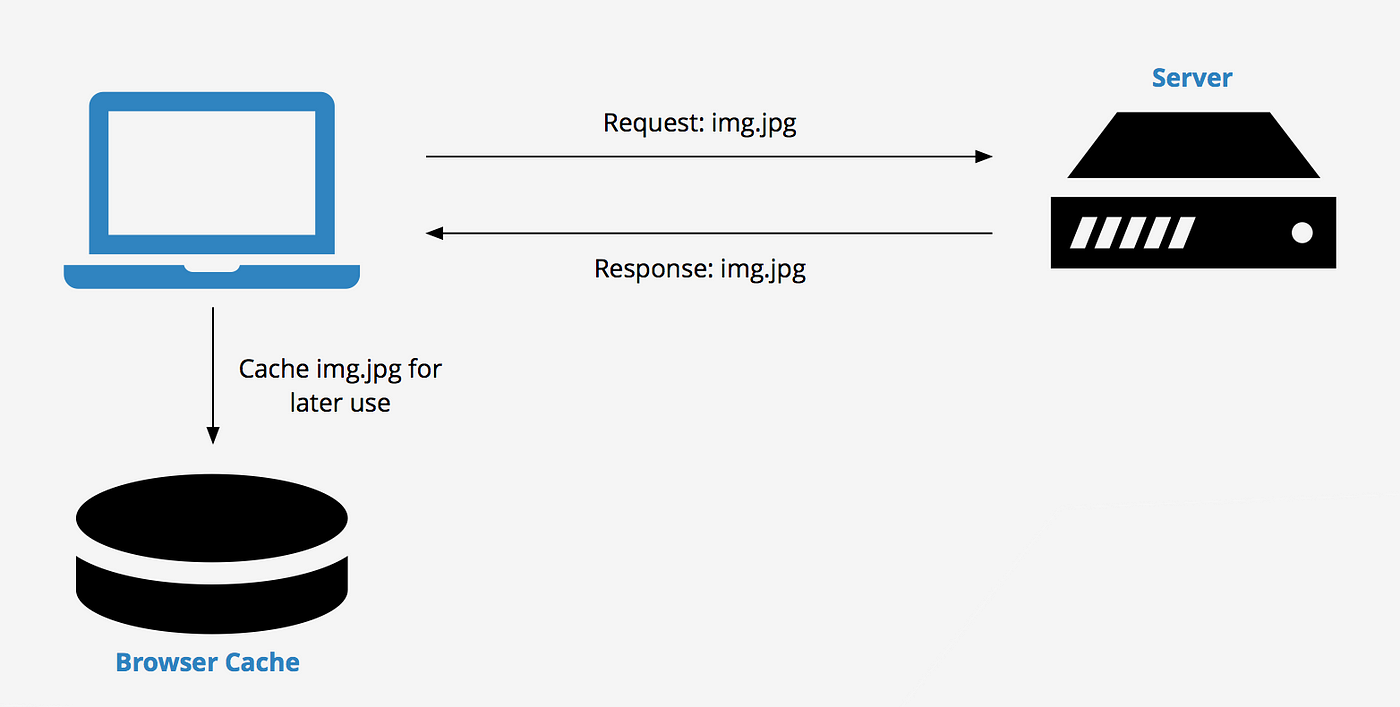
Client-side caching
Client-side caching involves storing data on the user’s device, such as in a web browser. This method is particularly useful for web applications that frequently access static resources like images and JavaScript files. By reducing the number of requests made to the server, client-side caching can significantly enhance the performance of a web application.
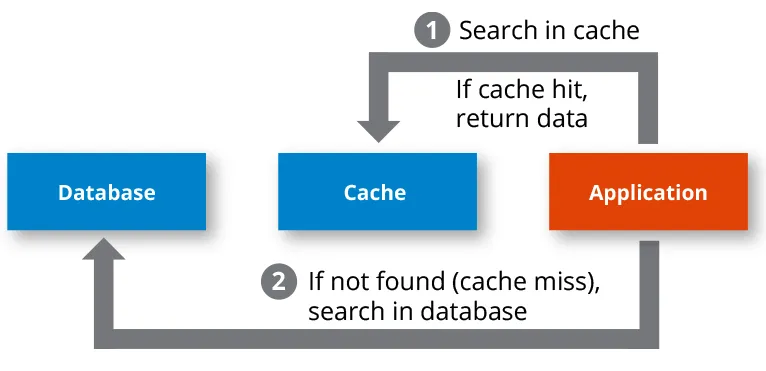
Let’s also understand few terms used in caching context: what are Cache Hit and Cache Miss state?
Cache hit: When a request for data is made using a unique identifier or condition and the requested data is already stored in the cache, the data is served from the cache instead of accessing the database. This situation is referred to as a cache hit.
Cache miss: In contrast to a cache hit, a cache miss occurs when the requested data is not available in the cache. As a result, the data must be retrieved from an external source, such as a database, over a network or from another data service.
Caching Strategies
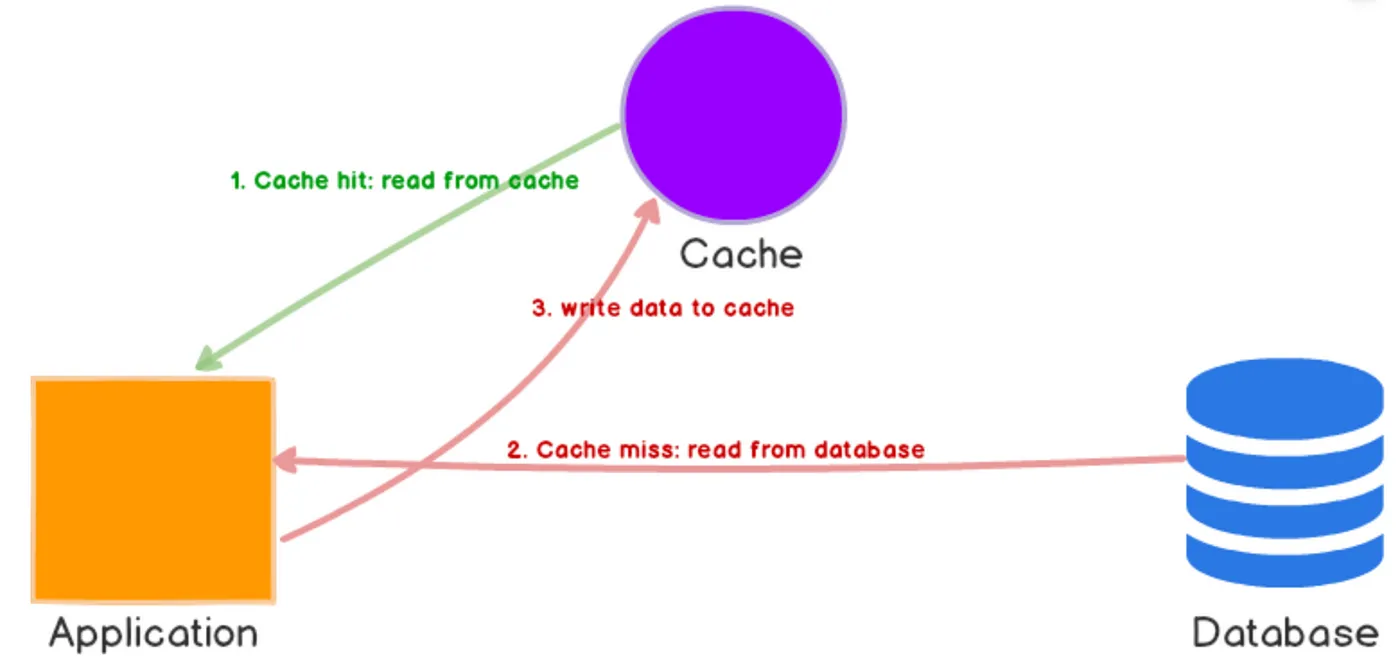
Cache-Aside
In this strategy, the application is responsible for managing the cache. When data is requested, the application first checks the cache. If cache is missed, it is retrieved from the database and then stored in the cache for future use. While this approach is straightforward and flexible, it requires careful management to ensure the cache remains up-to-date.
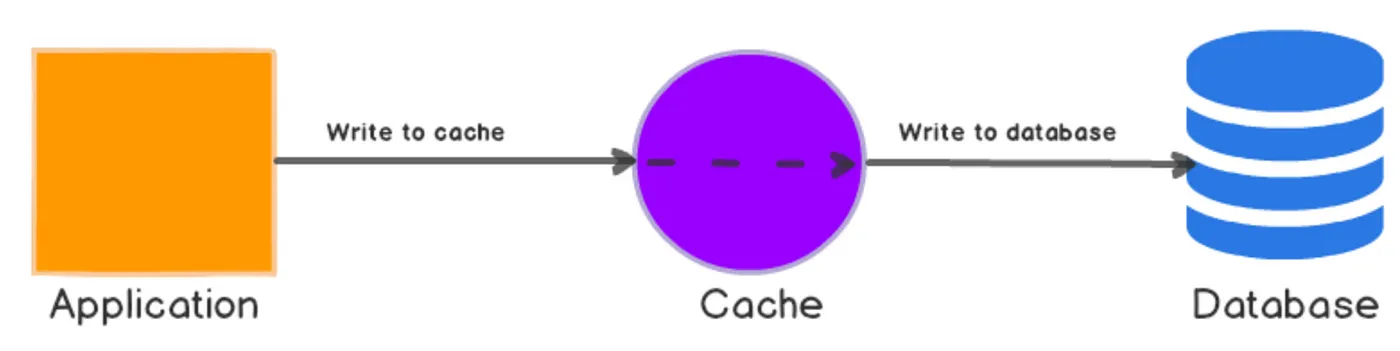
Write-Through
In this strategy, data is written to both the cache and the database simultaneously. When data is updated, it is written to both the cache and the database at the same time. This approach ensures that the cache always contains the most recent data. In systems where read operations significantly outnumber write operations, write-through caching can be efficient.
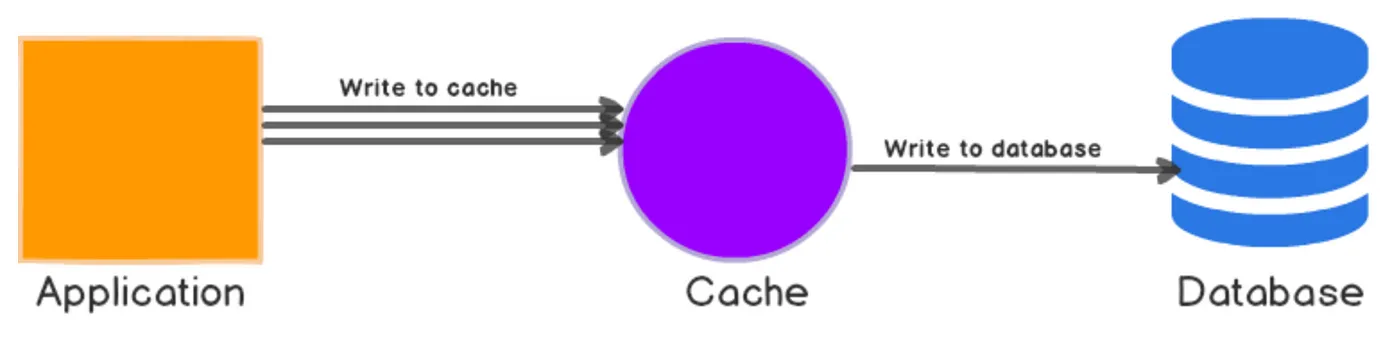
Write-Behind
In this strategy, data is written to the cache first and then to the database at a later time. This allows write operations to be faster, but it can lead to data inconsistencies if the cache is not properly managed. Write-behind caching can improve the performance of write-heavy applications by batching and delaying the write operations to the backing store (such as a disk or database). It is different from write-through as it delays the data update in database whereas write-through immediately updates data in database
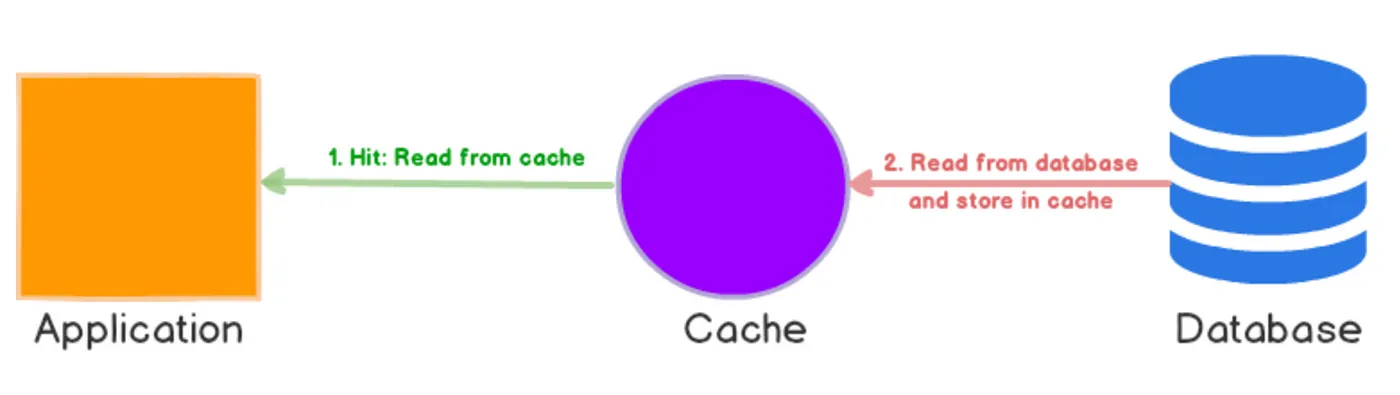
Read-Through
This approach prioritizes the cache as the main source of data. When data is needed, the cache is checked first. If the data isn’t available in the cache, it’s fetched from the database and then saved in the cache for future reference. This method is advantageous particularly when the database operates slowly or when data is accessed often but changed rarely.
What is the Cache Eviction policy?
Eviction Policy: As earlier, we know that cache is a limited fast memory access storage, this resource should be used wisely to improve the system’s performance. So we cannot cache all the data permanently in it. We also need to delete/evict the date entries from it when no longer needed or when we are out of cache storage. So to decide what data from the cache can be evicted we have to follow few policies as below:
- LRU: Least Recently Used
- LFU: Least Frequently Used
- MRU: Most Recently Used
- FIFO: First In First Out
- LIFO: Last In First Out
We can also assign TTL (Time to Live) to each entry of the data in the cache, which will auto-delete it when TTL time expires.
