


Summary
In this blog we’ll quickly cover what indexing is, how it is useful and how they work.
Basics
What is indexing and How it is useful
Indexing is a powerful tool used in the background of a database to speed up querying. Indexes power queries by providing a method to quickly lookup the requested data.
Simply put, an index is a pointer to data in a table. An index in a database is very similar to an index in the back of a book.. or if you relate it to this blog itself.. you can notice in the summary section, I have given an index in the summary section, now if someone wants to quickly go to section or subsection, their search is optimized and efficient in terms of time.
So to summarize, mostly an index is created on the columns specified in the WHERE clause of a query as the database retrieves & filters data from the tables based on those columns. If you don’t create an index, the database scans all the rows, filters out the matching rows & returns the result. With millions of records, this scan operation may take many seconds & this high response time
For a walk through for all the indexes i’ve created a sample mysql database with a sample table in it.. if you want to try it out for yourself follow the following commands for the setup and lets deep dive with hands on into indexes
CREATE DATABASE index_demo;then switch to index_demo database and create a users table
CREATE TABLE users (
name VARCHAR(20) NOT NULL,
age INT,
adhar_number VARCHAR(20),
phone_number VARCHAR(20)
);
INSERT INTO users (name, age, adhar_number, phone_number) VALUES
('Harry Potter', 20, 'AD1234567', '1234567890'),
('Hermione Granger', 21, 'AD2345678', '2345678901'),
('Ron Weasley', 20, 'AD3456789', '3456789012'),
('Albus Dumbledore', 115, 'AD4567890', '4567890123');

Understanding how to analyze a Search query
Lets start with analyzing a simple select query for users table (results are attached below).
EXPLAIN SELECT * FROM users WHERE phone_number = '1234567890';
now in the above screenshot
table: The table on which the search is executed.possible_keys: represents what all available indices are there which can be used in this query.key: It represents which index is actually going to be used out of all possible indices in this query.rows: It tells us how many rows our system searched through to find the record we queried for.
To see all the present indices you can run the following command you will see the output below.
SHOW EXTENDED INDEX FROM users;
now in the above screenshot
Table: The table on which the index is created.Key_name: The name of the index created. Right there are default values there as we’ve add no indexes to the table.Seq_in_index: If multiple columns are part of the index, the sequence number will be assigned based on how the columns were ordered during the index creation time. Sequence number starts from 1.Collation: Indicates the sorting order of the column within the index. ‘A’ represents ascending, ‘D’ represents descending, and NULL means no sorting.Cardinality: The estimated count of unique values in the index. Higher cardinality increases the likelihood that the query optimizer will utilize the index.Sub_part: The indexed prefix. It is NULL if the entire column is indexed; otherwise, it shows the number of indexed bytes for a partially indexed column. Partial indexing will be defined later.Packed: Shows how the key is packed; NULL if it is not packed.Null: Displays YES if the column can contain NULL values, otherwise it is blank.Index_type: Specifies the data structure used for the index, such as BTREE, HASH, RTREE, or FULLTEXT.Comment: Additional information about the index not covered by other columns.Index_comment: The comment specified for the index during its creation using the COMMENT attribute.
Different Indexes Available
Primary Index
A primary index is an index on the primary key of a table. It ensures that each row in the table can be uniquely identified and accessed efficiently.
The primary index enforces the uniqueness of the primary key. Each key value must be unique, ensuring no duplicate entries.
Index Structure: The primary index often uses a B-tree or B+-tree structure. These tree structures are balanced, ensuring that the time complexity for search, insert, and delete operations is logarithmic.
Lets start with creating a primary index
ALTER TABLE users ADD PRIMARY KEY (phone_number);once you’ve successfully created the index lets analyze it by running the command below
SHOW INDEXES FROM users;
lets analyze once agin our search query
EXPLAIN SELECT * FROM users WHERE phone_number = '1234567890';
notice that the rows column has returned 1 only, the possible_keys & key both returns ‘PRIMARY’ . So it essentially means that using the primary index named as ‘PRIMARY’ (the name is auto assigned when you create the primary key), the query optimizer just goes directly to the record & fetches it. It’s very efficient. This is exactly what an index is for
To minimize the search scope at the cost of extra space.
Clustered Index
A clustered index is a type of database index that sorts and stores the data rows of a table in order based on the index key. The key values of the clustered index determine the physical order of the data within the table. For a clustered index, it’s not mandatory that all the disk blocks are contagiously stored.
Consider you have the entire phone book of hogwarts. Now phone books generally have data sorted by names as shown
- data is sorted by last name (alphabetically in ascending order)
- then if last name is same, then it is sorted by first names (alphabetically in ascending order)
- then there are index pages which shows range of last names and on each pages (with maybe a sub index of first name on line numbers).
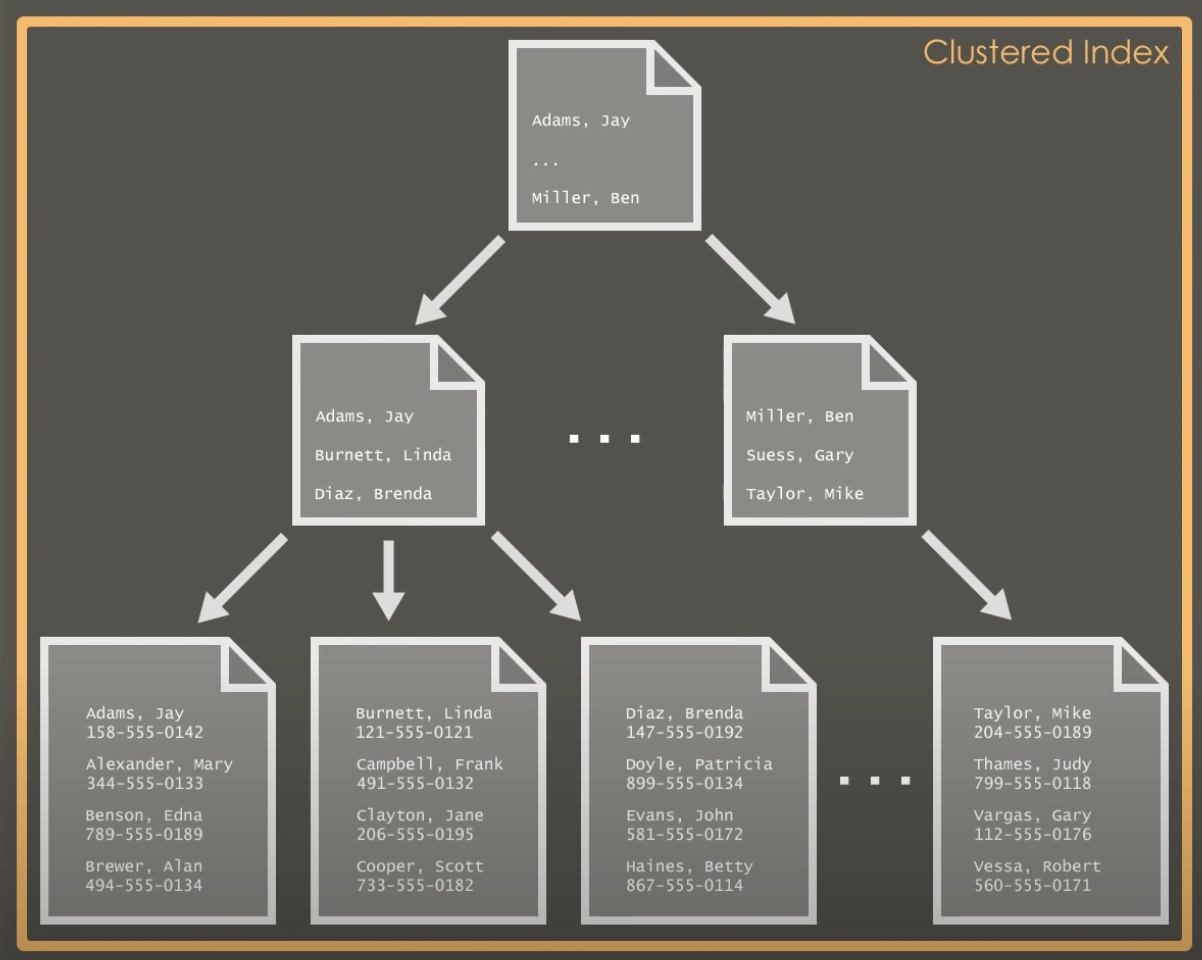
Now similarly clustered indexes work.
SQL server builds index record which allows query to navigate directly to the record without scanning the table entirely. We can consider that a clustered index is a B-Tree index whose leaf nodes are the actual data blocks on disk.
In most relational database management systems (RDBMS), we can’t have more than one clustered index per table. The primary key often defaults to being the clustered index because it is unique and defines the order of the rows. We already have a primary key on phone_number, it is our clustered index.
It comes in handy with range queries. lets analyze one of them
EXPLAIN SELECT * FROM index_demo WHERE phone_number > '1234567890' AND phone_number < '4567890123'
It is very clear the SQL Server efficiently navigates through indexes and directly lands at the 2 records that matched the range
Secondary Index
Any index other than a clustered index is called a secondary index. Secondary indices does not impact physical storage locations unlike primary indices. It is an additional index created on one or more columns of a database table to improve the performance of queries that do not involve the primary key.
Lets say there is a requirement for a regular search of records in users from their adhar number. In such cases we create an additional index on secondary index which is also maintained in the B+ Tree and it’s sorted as per the key on which the index was created. The leaf nodes contain a copy of the key of the corresponding data in the primary index.
So to understand, we can assume that the secondary index has reference to the primary key’s address, although it’s not the case. Retrieving data through the secondary index means we have to traverse two B+ trees — one is the secondary index B+ tree itself, and the other is the primary index B+ tree.
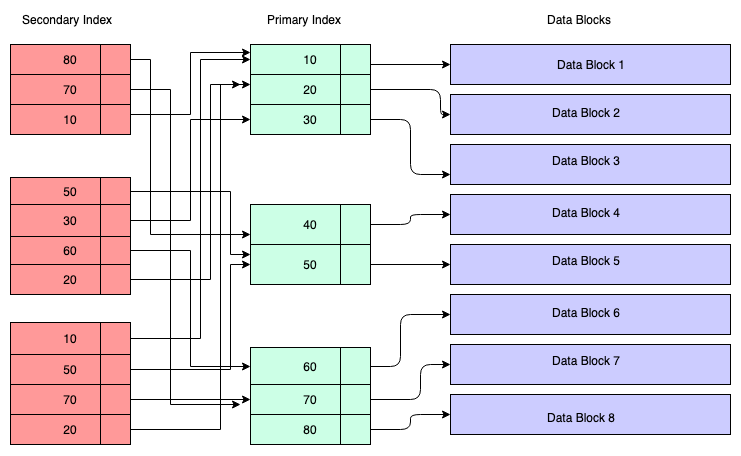
lets add one on users on adhar number
CREATE INDEX idx_adhar_number ON users (adhar_number);now if you check indexes on users table there will be 2 entries
SHOW INDEXES FROM users;
following screenshots show difference between indexed and non indexed search for query
EXPLAIN SELECT * FROM users where adhar_number = 'AD1234567';
Unique Index
A unique index is a type of database index that ensures all values in the indexed column or columns are unique. This means that no two rows can have the same value(s) in the indexed column(s). The unique key column can contain null values.
The following command shows how to create a unique key index
CREATE UNIQUE INDEX unique_idx_1 ON users (adhar_number);this makes sure that all the adhar_numbers are unique and if you try to insert a record with one similar to already existing record. Lets try it.. if you run the command
INSERT INTO users (name, age, adhar_number, phone_number) VALUES
('Harry Potter 2', 20, 'AD1234567', '1234567891');you get the error Duplicate entry 'AD1234567' for key 'users.unique_idx_1', indicating that an adhar number with the given value already exists and the entry we are trying to populate violates the unique_idx_1.
Now remember unique index is more of a constraint rather than and index.
If we run analyze adhar_number based query now we get the following results:
EXPLAIN SELECT * FROM users where adhar_number = 'AD1234567';
now if you look closely, you can see that there are 2 possible keys:
- unique_idx
- idx_adhar_number
and since unique_idx is more of a constraint than an index, idx_adhar_number is the key used for indexing.
What is the difference between key & index?
Although the terms key & index are used interchangeably, key means a constraint imposed on the behaviour of the column. In this case, the constraint is that primary key is non null-able field which uniquely identifies each row. On the other hand, index is a special data structure that facilitates data search across the table.
Composite Index
We can define indices on multiple columns, up to 16 columns. This index is called a Multi-column / Composite / Compound index.
Let’s say we have an index defined on 4 columns — col1, col2, col3, col4. With a composite index, we have search capability on col1, (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4). So we can use any left side prefix of the indexed columns, but we can’t omit a column from the middle & use that like — (col1, col3) or (col1, col2, col4) or col3 or col4 etc. These are invalid combinations.
The following commands create 2 composite indexes in our table:
CREATE INDEX composite_index_1 ON users (phone_number, name, age);
CREATE INDEX composite_index_2 ON users (adhar_number, name, age);If you have queries containing a WHERE clause on multiple columns, write the clause in the order of the columns of the composite index. The index will benefit that query. In fact, while deciding the columns for a composite index, you can analyze different use cases of your system & try to come up with the order of columns that will benefit most of your use cases.
Composite indices can help you in JOIN & SELECT queries as well. Example: in the following SELECT * query, composite_index_2 is used and in the following query composite_index_1 is used:
EXPLAIN SELECT phone_number, name, age FROM users;
Why do we use composite indices? Why not define multiple secondary indices on the columns we are interested in?
MySQL uses only one index per table per query except for UNION. (In a UNION, each logical query is run separately, and the results are merged.) So defining multiple indices on multiple columns does not guarantee those indices will be used even if they are part of the query.
MySQL maintains something called index statistics which helps MySQL infer what the data looks like in the system. Index statistics is a generilization though, but based on this meta data, MySQL decides which index is appropriate for the current query.
How does composite index work?
The columns used in composite indices are concatenated together, and those concatenated keys are stored in sorted order using a B+ Tree. When you perform a search, concatenation of your search keys is matched against those of the composite index. Then if there is any mismatch between the ordering of your search keys & ordering of the composite index columns, the index can’t be used.
In our example, for the following record, a composite index key is formed by concatenating adhar_number, name, age — AD1234567HarryPotter20.
| name | age | adhar_number | phone_number |
|---|---|---|---|
| Harry Potter | 20 | AD1234567 | 1234567890 |
How to identify if you need a composite index?
- If there are certain fields are appearing together in many queries, it is advisable to create a composite index.
- If you are creating an index in
col1& a composite index in(col1, col2), then only the composite index should be fine.col1alone can be served by the composite index itself since it’s a left side prefix of the index. - Consider cardinality. If columns used in the composite index end up having high cardinality together, they are good candidate for the composite index.
General Indexing guidelines
- Since indices consume extra memory, carefully decide how many & what type of index will suffice your need.
- With DML operations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not.
- Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
- Example: if you create an index on a boolean ( int 1 or 0 only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary.
- Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
- In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Thats all in this one folks.. let me know where i messed up in writing this :)